
Reign of the Front End
Since my last post in January 2014, I have thrown myself head-first into the world of JavaScript, Meteor, Node.js and MongoDB, working on two major (i.e., paid) projects plus one unpaid project.
The first paid project is a system to support sales functions of an established firm in the nutritional supplements space. The system is essentially an add-on to an existing CRM system. It uses the APIs to discover incomplete orders in the CRM system, then issues reminder emails to the prospects, and provides a convenient single-click method of completing those orders.
The second paid project is a multitenant SaaS in the eLearning space. The goal is to create a minimum viable product (MVP) to serve as a beta, and potentially to attract seed capital. This eLearning project has consumed most of my attention this year, and the challenges I have encountered are the impetus for this post.
In an earlier post, I suggested that Node.js and Meteor might yield an important indirect benefit: since JavaScript, a single language, is used for both client and server, JavaScript developers need not be pigeon-holed as back-end or front-end developers. Because the Meteor framework reduces friction on the back end, more intellectual horsepower might be freed up for the front end.
This could not come a moment too soon. Increasingly, modern websites are dynamic, responsive and reactive. They behave like installed apps. They push the limits of HTML5 and CSS3 leveraging complex stacks of JavaScript code to deliver the best possible user experience. They use animations, drag/drop, collapsible sections, momentum scrolling, popovers, type-ahead boxes, layer sliders, image galleries, maps, video feeds and graphs. Modern systems are expected to work equally well on touch devices and desktops, across all browsers.
We have little choice but to allocate more engineering bandwidth to the UI. Applications that look like they were designed before the tablet revolution will go the way of the dodo bird.
Nine Months
In the nine months since my last post, I’ve been immersed in the front end. I have come to see myself as a curator, scanning the globe for best-of-breed open-source offerings to facilitate our ambitious UX. Our front-end stack currently includes:
- Bootstrap 3-LESS
- Bootstrap Context Menus
- Bootstrap DateTime Picker
- Bootstrap Switches
- Bootstrap Tags Input
- Jasny Bootstrap Extensions
- Holder.js
- jQuery Sortable
- jQuery Touch Punch
- Selectize
- Amplify
- Touchspin
- Nearest
Evaluating open-source offerings can be time consuming. Bootstrap and jQuery add-ons tend to be in a constant state of flux as developers struggle to maintain compatibility with other systems, while simultaneously dealing with bugs and feature backlogs.
There are competing offerings, each with strengths and weaknesses. It can be helpful to first research what other developers are saying about the tools, and to take into account the sizes of their user bases.
It is necessary to install the tools and use them first-hand to prove that they will work harmoniously with the rest of the stack. You need to dive into the JavaScript code, frequently single-stepping through it with a debugger to diagnose issues. This process can disqualify a tool, resulting in a new round of searching and evaluation.
Be forewarned that choosing any tool will entail compromises: some features may work great but at the expense of others. You have to pick your poison.
Meteor Blaze
The Meteor Blaze release has been lauded as the solution for reconciling Meteor with jQuery. If you are not aware of the issue, it boils down to this: both Meteor and jQuery-based offerings want to control the document object model (DOM). When conflicts occur, you must intercede. Earlier versions of Meteor had template directives to allow you to declare certain areas of your web page constant (i.e., off limits for Meteor’s reactive updates). This would allow you to use tools such as jQuery Sortable, albeit foregoing reactive updates for constant regions.
The Blaze release is widely believed to have reconciled Meteor with many jQuery-based tools, but it is only a first step. The Meteor development team deprecated the constant template directive, implying that Blaze has solved the problem completely. I can say with considerable authority that this is not true. I have spent hours reconciling the behaviors of tools such as jQuery Sortable and Jasny Bootstrap with Blaze. I have reported issues to the Meteor development team and they have graciously acknowledged them.
Notwithstanding, Blaze is an enormous improvement. But there is still work to do to make it truly seamless, and until then UI developers will face extra effort, in some cases patching jQuery tools to get them to work correctly with Meteor.
Touch-Friendly
Desktop computers and touch devices have different event models. jQuery Touch Punch provides a means to convert touch events into traditional events so the same code can work on desktop and touch devices. But even when using Touch Punch, you have to be careful about the set of gestures your application supports. For example, there is no obvious gesture corresponding to right-mouse-click on a touch device, even though right-mouse-click is the standard event to display context menu or properties on desktop apps. This means that a modern web application will tend to avoid context menus, or at minimum provide a touchable icon (i.e., button) to display the menu, for example, a down-chevron, which seems to be all the rage these days:

The down-chevron should not always be visible, but should appear only when the division that contains the menu is “hovered” over or touched. I refer to this as a hover control. This clutter-resisting design pattern has been made popular by Facebook.

There is no touch equivalent for double-clicking, so that gesture should be avoided entirely.
Other differences include the absence of movable dividers (sashes) in the touch world, and the fact that drag/drop gestures must be reconciled with scrolling: in the touch world the two gestures can be ambiguous unless explicit “handles” are designated for dragging.
Layout Challenges
A modern web site must work well on desktop and touch devices, and with all popular browsers at any screen resolution. Bootstrap is helpful for coping with differences in screen sizes, but it is no panacea. Media queries can help in limited cases by targeting CSS rules to particular devices, but complexity grows with each exception added; therefore, it is necessary to code your HTML and CSS carefully and test frequently to avoid changes that break the UI on one or more platforms.
Speaking with other UI developers, I’ve come to realize that we’re all in the same boat. We’re all looking at our iPads wondering why our text doesn’t properly center on certain devices, or why our scrolling area extends beyond the right margin of the containing division, or why when iOS momentum scrolling is enabled we cannot drag items out of the containing division without the item being rendered invisible. With each new problem, we will use Google to find hits that might give us more insight, or might yield a solution. Time and time again, we will eventually find the magic recipe of CSS and/or JavaScript to overcome the problem.
Consider this: the popular website JSFiddle is loaded with tens of thousands of hacks to beat the browser into submission. That such a web site is even necessary speaks volumes about the current frustrating state of affairs.
Occasionally, when I complain about this, some hot-shot UI developer will respond “we use LESS” as if LESS somehow ameliorates these issues. The implication is that the problems are attributable to the CSS language; unfortunately, the problem isn’t the syntax of CSS, it is how browsers interpret the rules, particularly in complex cases with heavily nested divisions and dealing with issues like dynamic resizing, justification, visibility, scrolling and truncation.
We use LESS for all of our projects, specifically the advanced configuration offered by package Bootstrap-LESS. But LESS doesn’t address the core issue: the difficulty of finding the magic set of rules that will yield the desired dynamic-resize behaviors. Your pages must behave beautifully on any desktop or mobile device, at any size.
CSS requires discipline and continuous refactoring. The never-ending battle to keep your CSS DRY (don’t repeat yourself) is thankless. Unless you pay careful attention to class naming conventions and rule granularity, your CSS can spin out of control. Seemingly innocent changes will begin to have unwelcome side-effects.
Lately, I’ve been adding detailed comments to my CSS. Whenever I code a complex set of rules to overcome some layout issue, I write comments as clearly as possible to explain the intent of those rules, particularly in cases where the intent is to circumvent a browser bug. When the CSS has to be changed, comments regarding the original intent can help minimize costs.
The Front End Remains the Same
Last year, I went on a quest to find the best full-stack framework to develop modern web applications. I evaluated Ruby on Rails, Grails, ASP.NET and Meteor/Node.js. I imagined that I would find the best framework, try to learn it inside-out, and then use it to develop exciting applications.
But there was one thing that I didn’t fully appreciate: regardless of which framework you choose, the front-end issues will always be there. JavaScript, HTML5, CSS3 and all of the related challenges will be virtually identical. You’re going to have to worry about responsive design, layout, advanced behaviors touch devices and browser compatibility.
If you are a full-stack developer, you’ll spend the majority of your time in the front-end world of JavaScript and jQuery, regardless of whether your back end may be PHP, Django, Rails, JSP, ASP.NET or Node.js.
In my view, this reinforces the notion that Node.js (and particularly Meteor) is a great choice for new systems. Since there is no viable way to avoid JavaScript on the front end, why not go all the way and use it for everything?
When Will Our MVP Be Ready?
Notwithstanding great tools, project durations can be difficult to estimate, because no one can anticipate the snags that will arise. One thing is predictable: a given project will take longer than one would wish. A modern web site that works beautifully on all devices and has cutting-edge behaviors will be expensive.
Today, one factor seems irreducible: the cost of research. When you embark on creating a new subsystem that requires advanced behaviors, you’ll be forced into research mode to evaluate open-source offerings or custom coding. When you run into a snag, such as unacceptable behavior on some device, you will have choices (1) ignore the issue (2) consult with a knowledgeable colleague (3) fight harder by Googling, looking at the source code and experimenting.
In research mode, it is difficult to estimate how long it might take to find a solution. To estimate the cost, you must rely on your instincts, comparing each new challenge to similar challenges in the past. Sometimes you get lucky, but more often you don’t.
There will be plenty of dead ends, because no one can make the right choices every single time. New JavaScript offerings, platforms and services are constantly being introduced, and competitive pressures will compel you to learn about them and incorporate them into your applications.
Today, it may be drag and drop. Tomorrow it may be streaming video. The next day you may be working with 3D graphics in WebGL. You’ll have to learn many APIs, and use them defensively with robust error control and graceful degradation. Your system is not an island but an amalgamation of services, each of which is another potential point of failure.
We are all constantly learning. What we don’t know today, we will learn tomorrow. We must look at new challenges with a sense of wonder, with the eyes of a child. We must take the time to help and support one another, to share what we have learned.
Move Over LAMP, Make Way for JAMM
After working heads-down with Meteor and MongoDB for four months, I haven’t run into any show-stopping snags.
You’ve likely run into the acronym LAMP which describes an enormously popular application architecture based on Linux, Apache, MySQL and PHP. The combination of JavaScript, Meteor and MongoDB is so powerful and cost-effective, it deserves its own acronym. So move over LAMP and make room for JAMM (Javascript, Meteor, MongoDB).
Working with these tools has made me appreciate scrappy JavaScript, particularly when combined with powerful add-ons like jQuery and Underscore. JavaScript can be made modular, yielding key benefits of encapsulation and object-orientation (purists may argue but they’re splitting hairs). My own fears about leaving the Java “tribe” seem unfounded: everything you need for a typical data-centric project is available, open source, lovingly crafted by a growing list of true believers in Node.js and Meteor.
I think we’ll see more and more enterprise-class, cloud-based applications written using nothing but JavaScript. Many forward-thinking companies have been infected by this trend and have made enormous investments in JavaScript, albeit still using mature technologies such as PHP and AJAX. With deep pockets, they’ve spared no expense on their front-end code. Meteor lowers the bar, making JavaScript-centric, reactive front ends available to the masses at low cost.
But adjusting to these new tools can be disorienting, and I find myself comparing and contrasting JAMM to things with which I am more familiar. Over the past decade, I’ve been working on rule-based systems that conform to three-tier architecture.
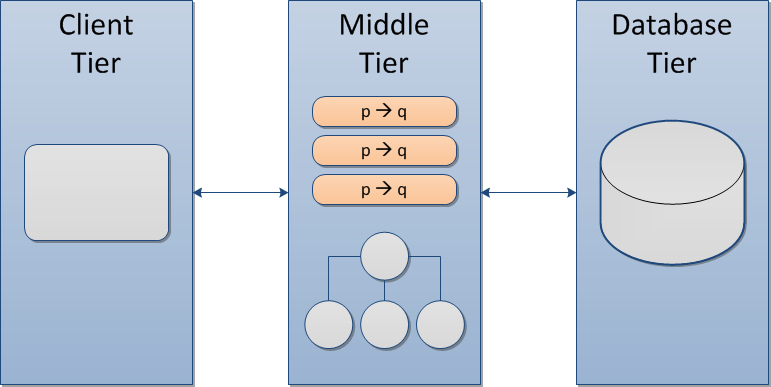
With this architecture, the client tier, typically a web page or hand held device, communicates with an application server that comprises the middle tier. The middle tier contains business rules that operate on a domain model (i.e., object instances that contain enterprise data). In most cases, the domain model is mapped to a database, and in the Java world, often using Hibernate, the leading object-relational mapping system.
By convention, in three-tier architecture, the client tier is typically regarded as “dumb” in that it merely renders facts that are derived by business rules in the middle tier. Granted, the front end has mechanical JavaScript code for things like animations, tabs and managing powerful widgets such as trees and tables, but typically no business logic.
In the three-tier approach, the database tier is frequently seen as nothing more than a storage system, but admittedly in many cases, firms fudge by coding some business logic in database-resident stored procedures and triggers that can technically be characterized as rules. People will argue about the merits of this, but I’ve honestly become fatigued by the controversy; it is mostly religion.
With three-tier architecture, the middle tier is king. The middle tier encapsulates a centrally-controlled domain model that is in a consistent, canonical form (i.e., objects). In theory, by centralizing business rules in the middle tier, cost can be reduced, and software quality can be improved.
Irrespective of whether potential benefits are realized, three-tier architecture is pervasive. A consensus about the viability of this architecture emerged in the early 1990’s and it has remained largely unchallenged to this day.
Tangible cost benefits of three-tier architecture can be difficult to achieve due to complexity. Object-relational mapping is not straightforward due to a set of technical problems collectively referred to as impedance mismatch. It has taken many years of focused effort for Hibernate to be regarded as production-ready. Even now, performance considerations make it likely that caching systems will be necessary, effectively carrying an object-oriented copy of frequently-referenced data in the middle tier.
It takes extraordinary effort to maintain the illusion that our data is represented as neutral objects when in fact the underlying data is stored in relational form. The cost of dealing with this complexity is real, including the difficulty of recruiting developers that have mastered object/relational technologies, but also in operations and technical support, where problems can be difficult to diagnose and correct. Much of this complexity and cost can be reduced by JAMM.
MongoDB as Object Authority
MongoDB stores and maintains data in a form that is functionally equivalent to a traditional middle-tier domain model. Because of this, there is no need to maintain a extra object-oriented copy of the data in the middle tier; instead, middle-tier rules operate upon objects in the database tier, which becomes the central authority for persistent and non-persistent facts. With this approach, the middle tier can be characterized as stateless.
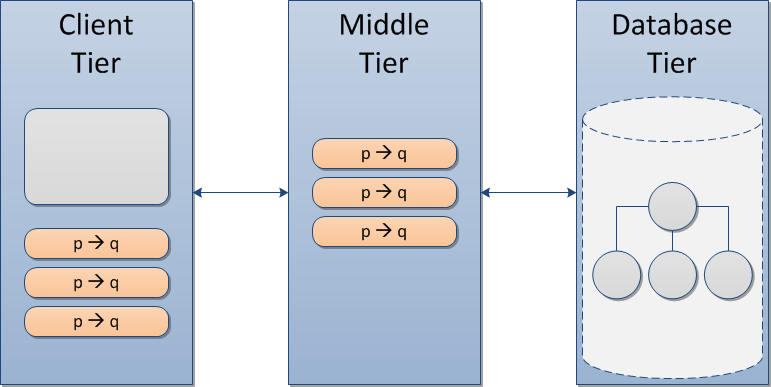
To an engineer familiar with traditional three-tier architecture, this shift in design can trigger alarms. I explored my own feelings about this, and found that they boiled down to visceral concerns about database performance.
To counter these concerns, it is important to understand that accessing data in MongoDB is much faster than an object/relational system. Given a Mongo ID of a document (tantamount to primary key), data can be accessed rapidly because:
- In many cases, the data to be accessed will already be memory
- The data may be indexed in extraordinary ways, including indexing every single field of a given record
- The database tier and middle tiers may in fact be in the same machine, reducing communications overhead
- There is no mapping overhead because the data is stored in object form
Rules in the middle tier can access just the data they need using granular MongoDB selectors (akin to database SELECT statements), and make state changes to MongoDB without carrying an object-oriented copy of the data.
With this approach MongoDB can be viewed as the state authority for both persistent and non-persistent data, supplanting the middle tier. I stress non-persistent, because MongoDB is so fast and convenient, it can be used to handle non-persistent data that would traditionally be kept only in the middle tier.
In short, we need to resist the tendency to look at MongoDB as just a storage system. It can be elevated to a higher plane to become the state authority, the keeper of canonical objects.
Rules on Client Tier
Because JAMM is implemented in 100% JavaScript, it is possible to deploy business rules to the client tier, the middle tier or both. Although purists may resist the idea of deploying business rules to the client, I have come to see this as a stupendous opportunity. Example opportunities for rules on the client include:
- Data validation without requiring a server round trip
- Data validation via calls to external systems without involving the middle tier (e.g., Google Places API)
- Conditional forms (i.e., certain parts of a web page being displayed or hidden based on answers to questions)
Meteor allows JavaScript rules to be moved indiscriminately from middle tier to the client or vice-versa, without programming changes. This permits you to deploy rules where they make the most sense, resulting in improved performance and user experience, and allowing the client to behave reasonably in the face of a spotty connection to the server.
Look forward to more applications pushing rules out to the client tier, and using middle tier services more sparingly for heavy number-crunching or for financial transactions where security is a concern.
Why I’m Sold on Meteor and Node.js
It has been almost two weeks since my last blog post. During this time, I’ve been working hands-on with Meteor, Node.js, MongoDB and Twitter’s Bootstrap framework. One of my main objectives was to find gotchas that might disqualify Meteor as a viable solution for upcoming projects.
During this time, I spent quite a bit of time working with HTML5 and CSS3 in the context of Bootstrap. Meteor, Node.js and MongoDB are so expeditious at dealing with the core issues such as data storage and retrieval that a larger percentage of time can be spent working on aesthetics, for example a responsive layout that works equally well on both hand-held and desktop clients, and also ensure that the application simply looks good and professional.
I broke down and purchased the fine book Discover Meteor: Building Real-Time JavaScript Web Apps:

This book helped me resolve a key mystery about Meteor, namely how the system determines which templates need to be refreshed when back-end data changes. Now that I understand it, I have to say that it is awesome, but please bear with me because you’ll need a little background to understand.
A meteor application is comprised of two “things” that must be developed in tandem:
1. Templates, which are HTML plus special Handlebars tags.
2. JavaScript template functions, helpers and event handlers.
Meteor templates are cleaner than traditional template-based development approaches like JSP, because there is never any JavaScript code in the template, and the interplay between the template and JavaScript code follows well-defined rules. Microsoft has gone in this direction with ASP.NET using the so-called code behind philosophy, where most C# or VB code can be in a separate file.
When Meteor processes your template, it will call into your JavaScript code at key control points to retrieve necessary data. For data-centric applications, the JavaScript code will typically call MongoDB to retrieve data, and that data will be cached in the browser-side Mini-Mongo as JavaScript objects. The Mini-Mongo data is directly accessible to the templates and is in the necessary format to feed the templates. There is no conversion overhead.
Now here is the magic: after Meteor processes your template, the system is smart enough to detect whether any of the data referenced by your JavaScript code has been changed, and to dynamically re-render the corresponding template(s). This automatic update occurs without a single additional line of coding, and is the key to Meteor’s so-called reactive behavior. Please take note of the word reactive, because I suspect that you’ll be hearing that more frequently in coming years. This is because Meteor, and similar platforms such as Derby, are poised to change user’s expectations regarding how web apps should behave, and there is no turning back.
But there was one central mystery: how can Meteor know if any of the data elements that happen to be referenced by my JavaScript code might have been changed, requiring that my template(s) be re-rendered? Meteor solves this problem in an elegant way that is transparent to the developer; moreover, by mastering a few simple concepts, developers can control the underlying machinery to connect to new data sources that are not known to Meteor.
Whenever Meteor calls into your JavaScript code, it first constructs an object called a Computation. The Computation contains many Dependency instances. Each Dependency instance represents a single data source that might dynamically change after your template has rendered. In practice, most of these Dependency instances correspond to MongoDB collections. The relationship between Computation and Dependency is many-to-many, so a given Dependency may be contained inside any number of Computation instances.
At any point in time, there is a so-called current Computation which is “active” at the time your JavaScript function is executing.
Meteor getter functions, particularly those that involve retrieval of MongoDB data, will automatically add Dependency instances to the current Computation. These Dependency instances are listeners for any changes in the underlying data source, and each Dependency knows the set of Computations that might be affected my underlying data changes.
Together, the Computation and its Dependency instances comprise a complete record of all reactive data sources that your template references, both directly and indirectly. In other words, as a byproduct of executing your JavaScript template-rendering function the first time, the system constructs a record of all reactive data sources that are inputs into your template.
Since the relationship between Dependency and Computation is many-to-many, a given Dependency knows the set of all Computations (and associated templates) that should be re-rendered if the underlying data changes. With the help of Websockets, Meteor listens to data state changes, and selectively re-renders only the affected templates. This is in contrast to standard JSP, ASP or PHP where the entire page would have to be refreshed on demand by the user, or via AJAX and jQuery calls to patch HTML after the initial rendering, requiring two separate code paths that do essentially the same thing.
Meteor unifies the code paths: the same code that handles the initial rendering handles dynamic refresh, so making a real-time web application carries no additional cost. Since real-time behaviors are inexpensive, you’ll see them more and more frequently, and static approaches such as JSP will seem clunky and “legacy” by comparison.
I’m particularly excited about the possibilities using Meteor together with HTML5/CSS3 animations, Google Charts and RIA frameworks such as Sencha ExtJS. Consider these possibilities:
1. Smooth-scrolling tables of data that dynamically roll as data is added similar to the ending credits of a movie
2. Google Charts that dynamically update as data is changing
3. Table and tree controls that are dynamically updated as user collaborate on a shared data model
Such reactive behaviors will likely become hallmarks of modern web apps. Start-ups can take advantage of these technologies to differentiate themselves from well-established competitors, at least in the near term.
So, if Grails is a carrier battle group, and Ruby on Rails is a rickety pirate ship, I would say that Meteor/Node.js are the Oracle catamaran: minimal, streamlined, modern and super fast to develop.
Opinions Forming on Rails – More on Node.js
I have an opinion forming about Rails. It does seem to handle everything, but Rails is making the hair on the back of my neck stand up.
If one could compare Grails to a carrier battle group, Rails might be seen as a rickety pirate ship. Although Ruby (the language) is fine, Rails seems clunky, somewhat dated. It reminds me of Oracle: cumbersome install, heavy reliance on command line. It took quite a bit of set up to get through the tutorial. I had to assign very specific version numbers to all of the gems (plugins) in order to get through the tutorial as written. That bothered me.
Moreover, the Rails stack is a little scary because there is so much magic going on. I’m sure it works great on the happy path, but what if you have to stray? Also Ruby on Rails feels like a cult. Rates for Rails developers are high. The phrase The Ruby Way makes my skin crawl. My wild-wolf instincts say run.
I’m of the opinion that model-driven design and MVC will save money if done right. This is evidenced by the fact that many popular frameworks revolve around a domain model. Although all of the full-stack frameworks claim to conform to MVC (or MVVM), they appear to have different ideas about what this means.
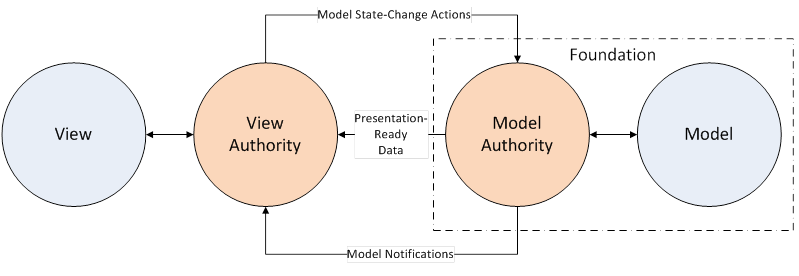
This diagram depicts a pattern that I call Absolute MVC, a phrase we coined at Corticon. A user action, such as inserting a new row into a table, triggers a message to the model authority in the back end. The model authority knows how to change the model correctly in response to the user action. A single message may result in substantial changes to the model in a transactional manner.
Full-stack frameworks often refer to the combination of the view authority plus the model authority as a controller.
In Absolute MVC, we formally separate the model authority from the view authority. The view authority is concerned only with refreshing the view, and only in response to state-change notifications from the model authority.
Unfortunately, the full-stack frameworks don’t actually work like this, notwithstanding that they claim to implement MVC. The key reason is technical, and it boils down to this: there was no convenient way for the browser to receive an asynchronous notification from the back end. In other words, there was no reliable way for the model authority to notify the view authority that the model state had been changed. Until now.
As of this writing, there is standardized way to do this called Websockets (RFC 6455). Moreover, there is a cutting-edge framework called Meteor (which works with Node.js) that takes advantage of this new capability. Meteor is the first (and only) framework that I have encountered that implements Absolute MVC with the browser.
If you’re used to traditional web development (e.g., PHP, JSP, ASP), you have to see Meteor with your own eyes, but consider this. The browser views are bound to a shared data model. If any user changes the data model, all browsers update instantly. There is no polling. The function is driven by an asynchronous message from the server to the browser(s).
Meteor maintains an object cache in the browser that is synchronized with the Node.js server. All of this is transparent to the developer, who can behave as if all of the information is stored locally. The system allows the developer the illusion of being able to directly access data inside MongoDB from client-side JavaScript.
This architecture avoids a lot of the clumsy implementation issues that surround the traditional request/response/redirect patterns that plague JSP and the like. The code to access data is simple, and you have to see the Meteor screen cast to fully appreciate this. The server delivers data to the front end, and HTML rendering is done in the browser.
However, one drawback to consider is that Meteor and Node.js are new, and many subsystems are still in their zero (beta) releases. The good news is that Meteor apparently had a recent injection of financing which should keep them around for a while.
It is no exaggeration to say that Node.js combined with something like Meteor could become popular very quickly, because the potential savings are enormous.
I’m currently working on a “spike” to get a Hello World application up on this stack to see it with my own eyes, and I’ll post my findings here.
Rails Demonstration Application Working
Today, I got my first Rails application with a domain model working. The application was pretty simple, and it is really only a first step.
I’m going to take a brief detour from Rails to check out Node.js and some related technologies, including MongoDB. Although I’m having good success with Rails, I was reading something today about JavaScript that has me rethinking my position on Rails. Take a look at Node.js job posting trends.

JavaScript is the front end language, and that isn’t going to change. By simply accepting that reality, and by standardizing on JavaScript on the back end, we can likely reduce development costs by standardizing on a single language.
Consider also that PhoneGap cross-platform development for iOS and Android uses JavaScript.
These considerations, combined with the availability of several viable domain modeling frameworks for JavaScript (e.g., Backbone.js) is going to make me take a deeper look at JavaScript on the back end.
What if a couple of years from now, we’re all programming in JavaScript? Stranger things have happened.
Ruby on Rails
Yesterday, I started reading through the Book of Ruby (Huw Collingbourne), which is a bible for Ruby developers. This book focuses on the Ruby language itself. Ruby syntax reminds me of Pascal but with significant improvements.
In terms of capability, Ruby seems roughly equal to Groovy, offering meta-programming and closures. I feel that the jump from Java to idiomatic Ruby would be about the same as a jump from Java to Groovy. The key is taking advantage of all of the new language features to simplify code.
Ruby is dynamically typed. This means errors can sneak in where they would be caught at design time with a strongly-typed language like Java. Fortunately, Rails supports a super-disciplined, test-everything philosophy, which is a good idea in any case. This makes me believe that the actual benefits of strict typing may be overrated, so long as ample unit testing is performed. We Java developers may have been brainwashed into thinking that strong typing is a panacea.
I was drinking from a fire hose, running through the Ruby on Rails Tutorial (Michael Hartl). The first chapters of the book get you set up with the proper development infrastructure.
I’ve evaluated a couple of Ruby IDEs and ultimately I’ve settled on RubyMine.
RubyMine is crammed with features and has been working beautifully thus far. There is also an Eclipse-based IDE called Aptana, but my sense is RubyMine is the better choice. One drawback with RubyMine is that it is Swing-based, so it has a slightly clunky look and feel; however, the developers have done a great job making the best of things within that constraint.
The Rails tutorial has also given me a crash course in Git and GitHub. If you have nothing better to do, you can actually visit my first application (first_app) here:
https://github.com/sotarules/first_app
Finally, this tutorial stepped me through the process of setting up Heroku, which is apparently a preferred cloud provider for Rails.
I’m proud to say that this application is running in the cloud as expected, but it doesn’t do anything useful. This was just an exercise to ensure that all infrastructure hurdles have been dealt with before actual development begins.
I’m planning to develop my first demonstration app next week. Stay tuned for excitement and surprises.